Tools
PDF Table Extractor
In an effort to map supply networks the consortium found many supplier lists were published in structured tables, but only available as PDF reports, making them difficult to translate into spreadsheets.
To tackle this challenge, CERTH developed a PDF Table Extractor tool towards the end of 2017, which would enable scraping of such PDFs into spreadsheet format. The tool was developed based on the Java library of Tabula and is available online.
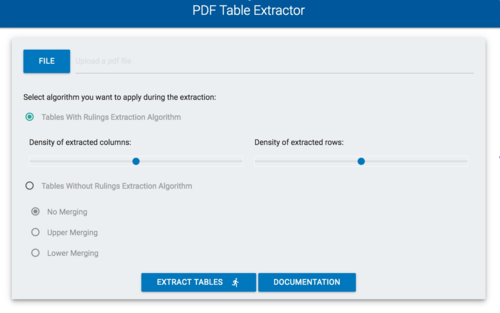
The PDF extractor addresses a need by the ChainReact consortium among many others working in ESG and supply chain transparency, to scrape public data from tables in PDF reports.
It has allowed the extraction, and then mapping of around 13,000 relationships between suppliers and companies sourcing from them.